
Would “The Great Parallel” for Embodied AI Come True?
World model is having its moment, but we think it's the wrong debate


TL; DR
NVIDIA’s Jim Fan calls it “The Great Parallel” at Sequoia AI Ascent this year—the thesis that embodied AI will follow the same arc as LLMs: world modeling as pre-training, action fine-tuning as alignment, physical RL as the reasoning layer. It’s a compelling vision, and $5B+ has already poured into world model companies betting on it. While world models hold tremendous promise, few are asking what’s actually blocking convergence in embodied AI. This piece maps the substantial divergence still present across model architecture (VLAs vs. world models vs. others), data scaling strategy, and world state representation, and identifies structural bottlenecks that make the Great Parallel far from reach yet. Understanding these bottlenecks, we believe, is the prerequisite for identifying where the durable startup opportunities actually lie.
Table of Contents
There is a lot of divergences in embodied AI, even though world models hold promise
Would “The Great Parallel” come true?
Opportunities for startups
Definition
Before we dive in, let’s define what we mean by “world model” in the context of this article. We draw from the recent world model survey by Jingtao Ding et al. from Tsinghua University, which offers a definition we find a fit here:
World models are structured around two primary functions: (1) constructing internal representations to understand the mechanisms of the world, and (2) predicting future states to simulate and guide decision-making.
In the context of embodied AI, decision-making refers to how a physical agent such a robot, autonomous vehicle, or similar system selects actions to accomplish goals in the real world.
There is a lot of divergences in embodied AI, even though world models hold promise
Model Divergence: VLA vs. World models vs. Others
Vision-Language-Action (VLA) models map observations (images, language instructions, and robot state) directly to robot actions. Specifically, it holds the promise of generalizable embodied control: the pretrained Vision Language Model (VLM) backbone provides rich vision-semantic priors, and an action decoder translates this semantic understanding into continuous motor commands. However, VLMs are typically pre-trained on static image-text datasets, and limited spatiotemporal priors are inherited. Fundamentally, VLAs operate in text space - a symbolic, action-agnostic abstraction that may lack critical information about the physical world such as the spatiotemporal understanding.
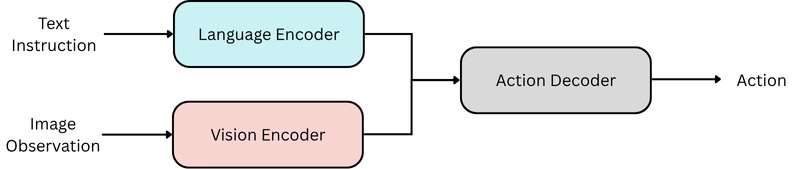
More recently, world modeling has been widely discussed as a paradigm shift away from VLA-based approaches in robot learning. As noted above, many modern world models are video-model-based robot policies that pair a diffusion backbone, which inherits rich and diverse spatiotemporal priors, with an inverse dynamics model to extract control actions from generated video--an approach pioneered by Yilun Du et al. in UniPi. A newer line of research goes further, jointly predicting both actions and future world states, as seen in Nvidia’s recent DreamZero paper. The deeper shift is in what the robot learns: rather than how one specific robot should move, it learns the physical dynamics of the world itself, which transfer across embodiment types. Because a world model is action-conditioned, it can also be queried interactively, letting the robot reason through counterfactuals (”what happens if I do this versus that?”) and plan in real time. VLAs, by contrast, tend to map memorized scenarios to actions in a single shot, and so struggle in the unseen, unstructured environments that were never demonstrated in training. That being said, it’s still open research problem to do reasoning in the pixel space, therefore most world models currently lack reasoning capabilities.
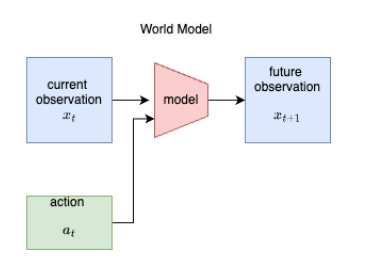
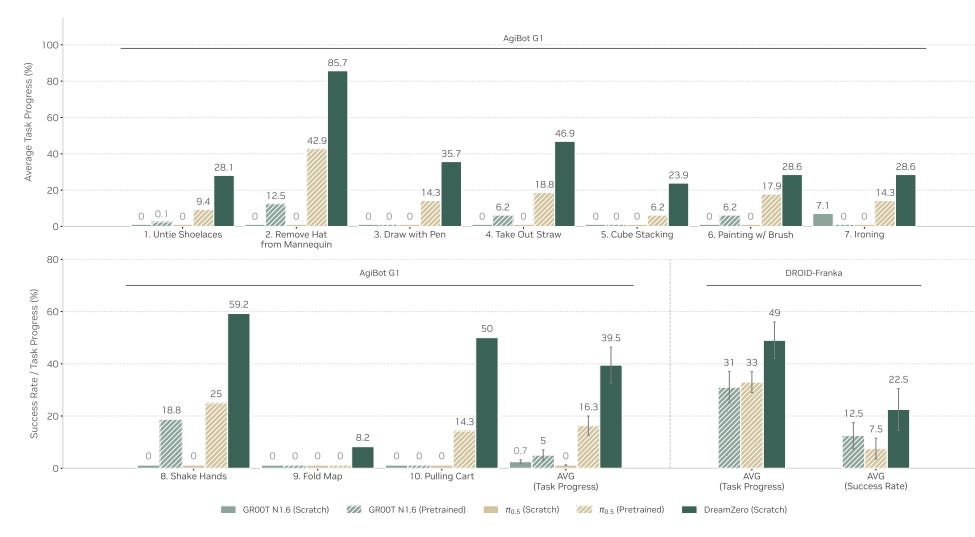
Indeed, several recent papers demonstrates world model’s superior sample efficiency and generalizability over VLAs. Nvidia’s DreamZero achieves a 2x improvement over state-of-the-art open-source VLAs on unseen tasks and environments. It also unlocks training data structures that VLAs cannot exploit efficiently: where VLAs require repetitive demonstrations (e.g., “pick up the cup” performed 50 times), a single DreamZero episode is a continuous 5-minute teleoperated sequence spanning roughly 42 distinct subtasks.
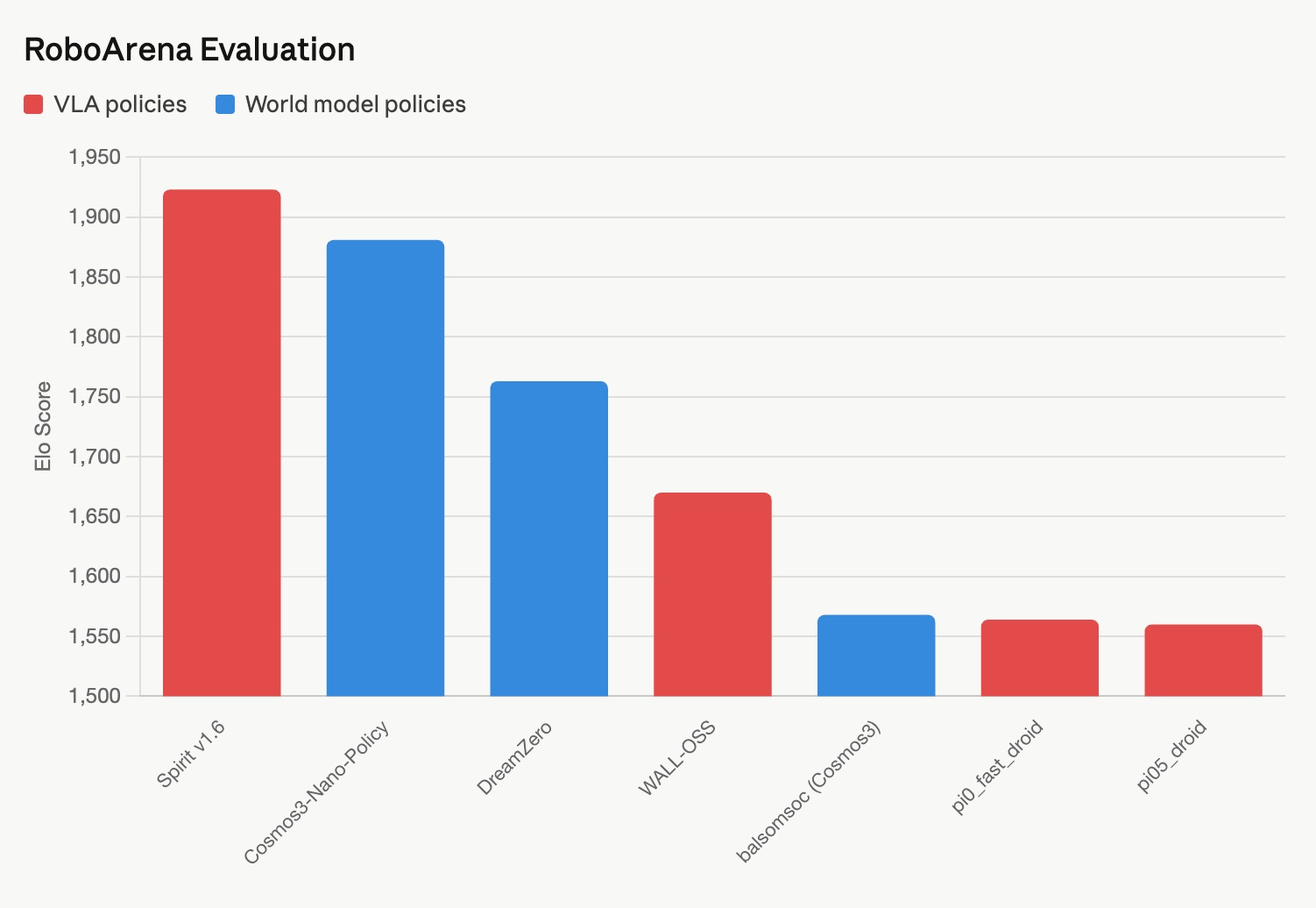
However, the field is still very early and evolving, and it’s unclear which model architecture will be the winner. PI openly admits that they have spent some time betting world models would dramatically beat VLAs on task generalization; the bet initially paid off, until its own VLA baseline caught up as more data came in and also began showing generalization. The RoboArena leaderboard showcases a highly dynamic landscape where the score continues to shift significantly within the ongoing architectural debate between VLA models and emergent world models.
That said, some researchers think a video-generation backbone remains suboptimal in the long run and will not deliver physical intelligence on its own. The argument is that robotics does not need pixel-perfect video fidelity, and that human intelligence draws on far more diverse sensory information than vision alone, from force to touch to sound. Generalist’s GEN-1 embodies one response to this critique: it is neither a VLA nor a world model, with roughly 99% of its parameters trained from scratch on half a million hours of UMI-style physical interaction data captured from low-cost wearable devices. A second camp pursues hybrid architectures that fuse the two paradigms, pairing a VLA’s semantic understanding for high-level task decomposition with a world model’s predictive, generative dynamics, on the logic that each compensates for the other’s weaknesses. The most expansive bet is the omnimodel, exemplified by Nvidia’s recently announced Cosmos 3, which combines vision reasoning, world generation, and action prediction in a single system and natively understands and generates text, images, video, ambient sound, and actions rather than stitching together separate modules.
Data Scaling Divergence
The recent launches from a few robotics foundation model companies in the past couple of months indicated that there is also no convergence on what data to collect and scale. Generalist collected half a million hours of UMI-style physical interaction data, setting a precedent for UMI-style data scaling as the new substrate for robotics foundation models. Physical Intelligence (PI)’s π0.7 leverages an VLA model to use very diverse data, which is a combination of robot data in diverse environments in the wild and in-lab (demonstration data, failure data, autonomous data, across different robot platforms including static and model, with single arm or bimanual) and non robot data (multimodal web data, egocentric human data). LingBot-VLA is currently one of the largest single open releases trained on 20K hours of teleoperated robot data. Rhoda believes that web video is the most scalable data source capturing the dynamic physical world, and their system is pretrained on hundreds of millions of hours of web video data.

Even though these teams are betting on dramatically different data strategies, they seem converging on the similar principle: scaling data and curating data to the right quality matters more at the moment than the model architectural label.
If we believe embodied AI follows a scaling law like LLMs, how can we reach internet-scale data to solve robotics? The scale of the challenge is stark: as Ken Goldberg famously framed it, robotics faces a 100,000-year “data gap” relative to the data behind today’s large language and vision models. Closing it means finding data sources that actually scale. From first principles, large scale web video is the most abundant vision data the industry could leverage, if a model figures out how to learn the dynamics well and transfer the learning onto robotics. Teleoperated robot data is the least scalable, as it typically requires high setup cost to collect those data and the data also lacks diversity. Sitting in the middle is the data collected through lightweight wearable hardwares such as head-mounted, wrist-mounted cameras to collect a first-person perspectives, i.e. egocentric, or an UMI (University Manipulation Interface)-style hardware framework or sensor-incorporated gloves, which learns directly from human demonstrations without requiring expensive, robot-in-the-loop teleoperation. The holy grail is to use as little robot data as possible, but current robot policy isn’t yet generalized enough for teleoperation to go away any time soon.
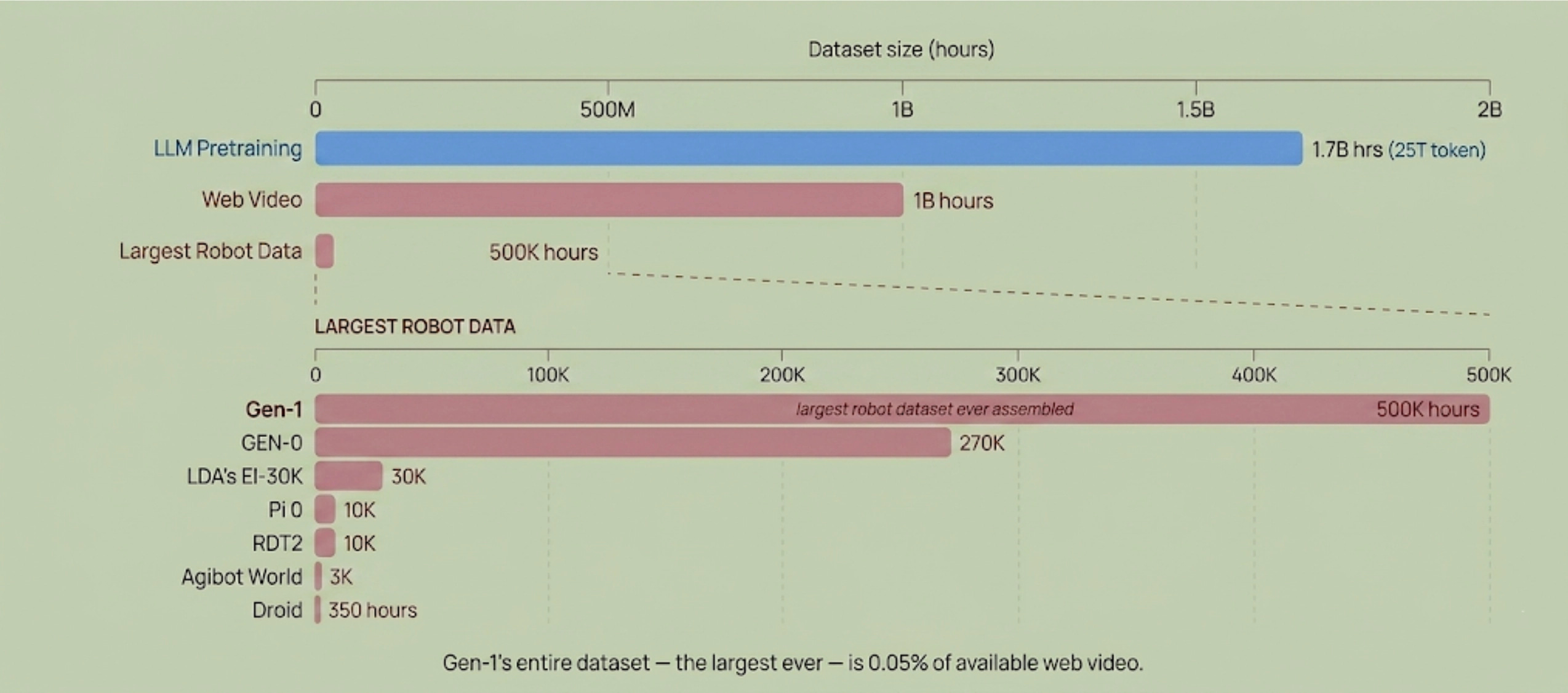
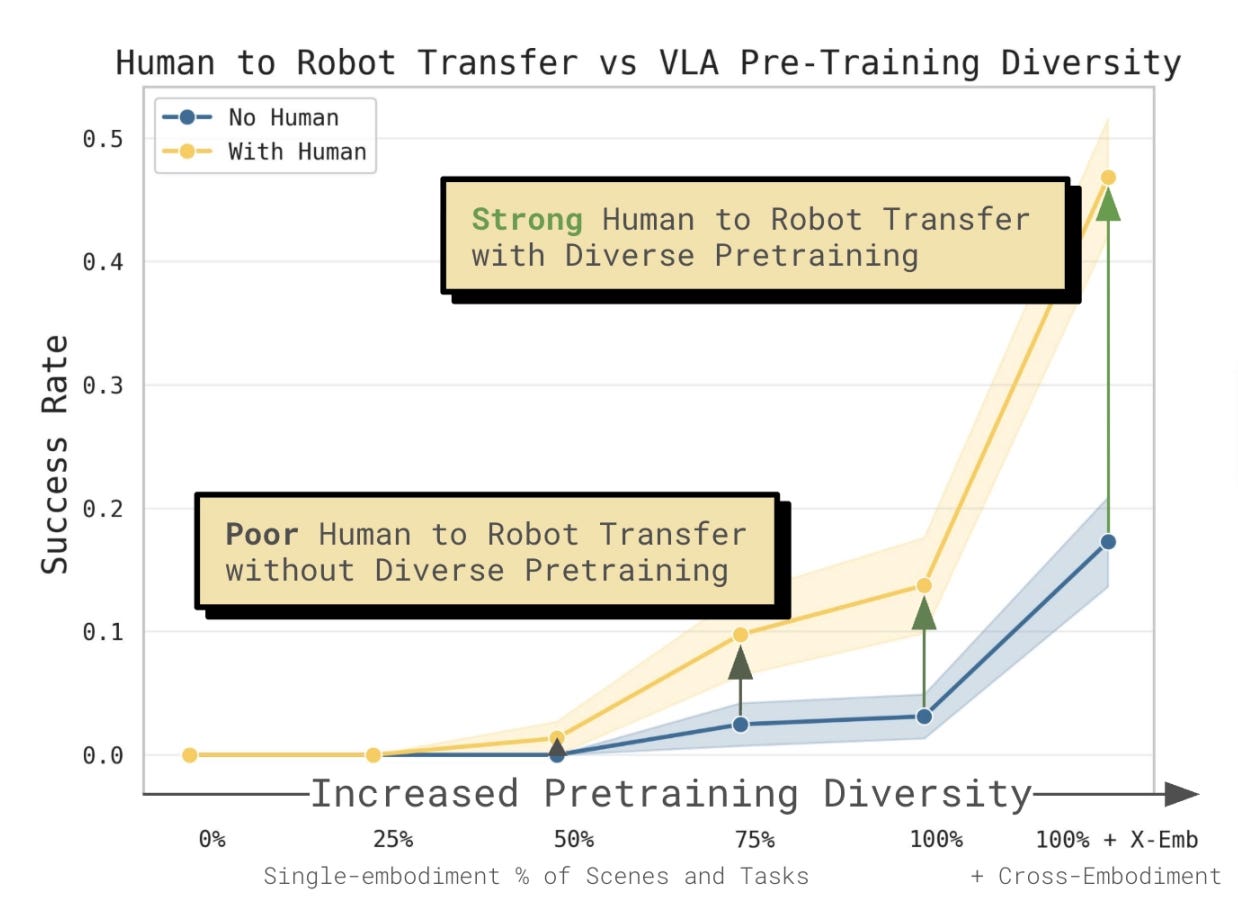
Recent work Chelsea Finn presented at a CVPR 2026 Workshop offers an early signal of what’s possible. Human-to-robot transfer is emerging when pre-training data reaches sufficient diversity across scenes and tasks. Critically, with a diverse enough robot data foundation, incorporating human video data can nearly double task success on novel generalization settings the robot has never directly observed. The performance ceiling scales with data diversity, but the field has yet to establish what “enough” looks like, or how to get there efficiently.
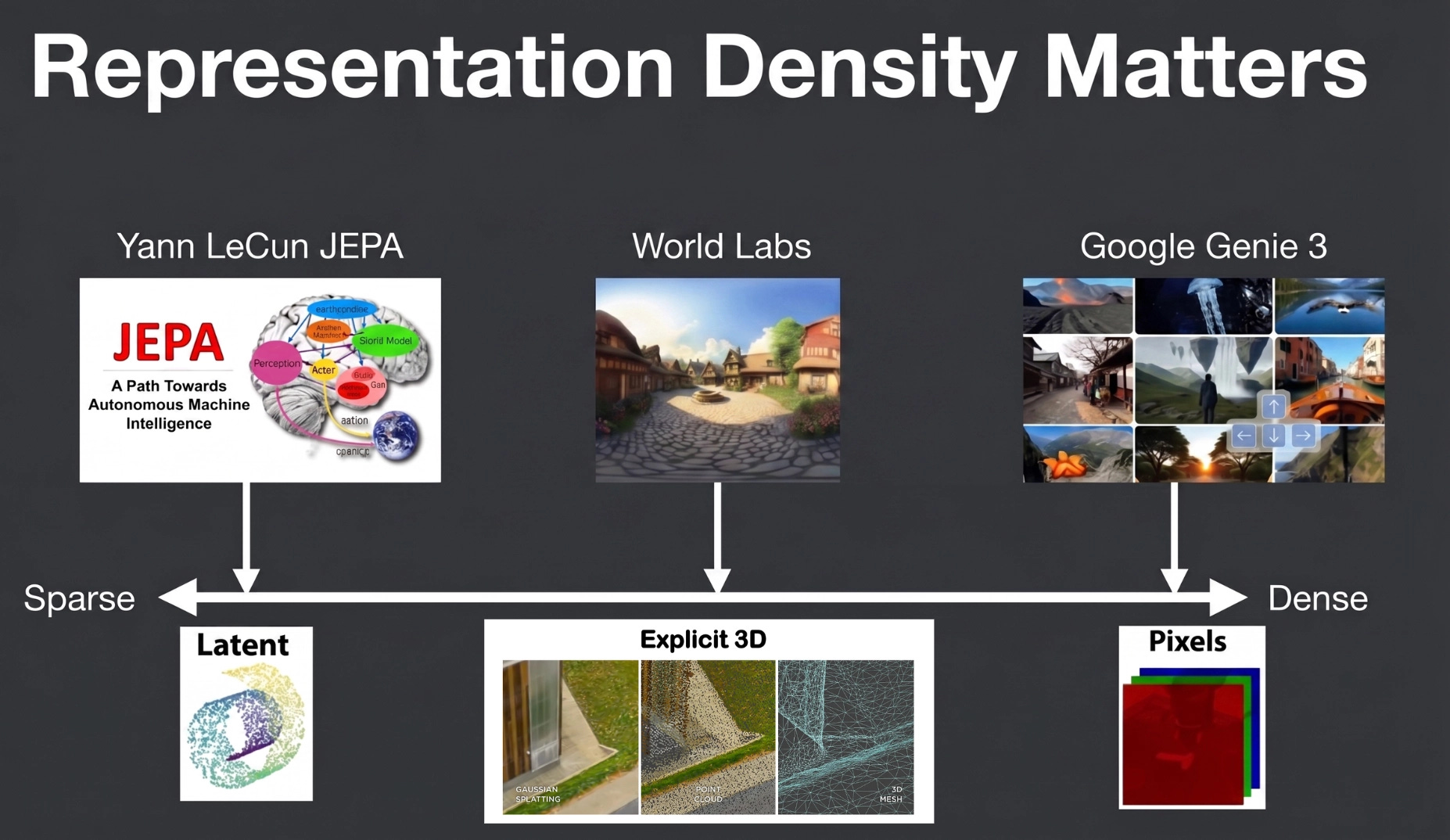
Representation Density Divergence for World Models
Given the nascency of world models, there are structural debates—both in academia and industry—on how to best represent a given world state. Specifically, they vary in the level of abstraction and that leads to trade-offs in modeling capacity, sample efficiency, generalization, task alignment, interpretability, and computational cost [ref]. Currently, there are three main school of thoughts: Pixel-based, latent-based, and explicit 3D geometric representations.
Pixel-based models directly predict the world with raw pixels and the density of the representation ensures photorealism and a lossless projection of the world. However, it could prioritize pixel reconstruction over semantic significance and could lead to redundancies. Furthermore, video generative models that does frame-by-frame prediction is computationally expensive. When used in embodied AI, the model may waste immense capacity trying to predict high-frequency details that don’t actually matter for decision-making (for example, individual leaves moving on a tree).
Explicit 3D geometric models prioritizes structure: rather than reconstructing every pixel, they encode the scene’s geometric configuration directly—the positions, shapes, and spatial relationships of its contents—as the primitives the model reasons over. Several approaches sit at different levels of abstraction. Particle-based methods scatter dense discrete points across objects to capture both surfaces and volumes; Keypoints are far sparser, retaining only a few task-relevant points with semantic meaning; and object-centric representations is the most abstract, modeling dynamics at the level of interacting objects. Each suits different tasks: object-centric representations excel at multi-rigid-body manipulation, while particles better capture deformable and non-rigid objects. [ref] Beyond static states, Wenlong et al.’s PointWorld represents actions themselves as 3D point flow, an embodiment-agnostic formulation. Our portfolio company Sancho uses a particle-based representation, which they have found computationally efficient and capable of robust long-horizon navigation.
Latent-based models represent the world with a compact set of features in a latent space that are necessary to predict the future, and wins by having stronger learning and computational efficiency as well as greater generalization [ref]. Yann Lecun has been a long-time advocate of latent-based models—proposing the Joint Embedding Predictive Architecture (JEPA) in his 2022 paper. JEPA sets the training objective as predicting the next latent vector and trains specialized encoder to eliminate irrelevant details that are not conducive to the prediction. The Dreamer family of papers by Danijar Hafner et al. show that an agent learns behaviors in latent imagination.
To reconcile these structural debates, an emerging school of thought advocates for breaking the rigid boundaries between these individual paradigms in favor of multi-level hybrid world representations. In their 2026 perspective paper, Jiajun Wu et al. propose a structured, Markovian world model that leverages explicit representations to ground the world model directly into a foundation model’s reasoning space—keeping learned concepts interpretable—while relying on implicit latent features to capture the expressive, dense complexities of geometry, texture, and physics. Crucially, this hybrid approach is an exciting research direction to build towards robust and generalizable world models.
Overall, there is still substantial divergence in model, data, and representation space within embodied AI. After all, the LLM field looked similarly fragmented—recurrent architectures like RNNs, LSTMs were dominating the field, convolutional neural network were promising, and attention mechanism were nascent. However, when “Attention is All You Need” came out in 2017 and established transformer as the defacto architecture of the LLM era, the industry took off exponentially. Some might argue embodied AI is poised for the same kind of convergence.
Would “The Great Parallel” Come True?
In 2026, NVIDIA’s Jim Fan proposed “the great parallel”: the thesis that embodied AI will follow the same technology growth arc as LLMs. The foundational first step is consolidating on a unified pre-training paradigm, both in terms of model architecture and data scaling laws. But would we see convergence of pre-training paradigm anytime soon? If so, what would be the speed of convergence?
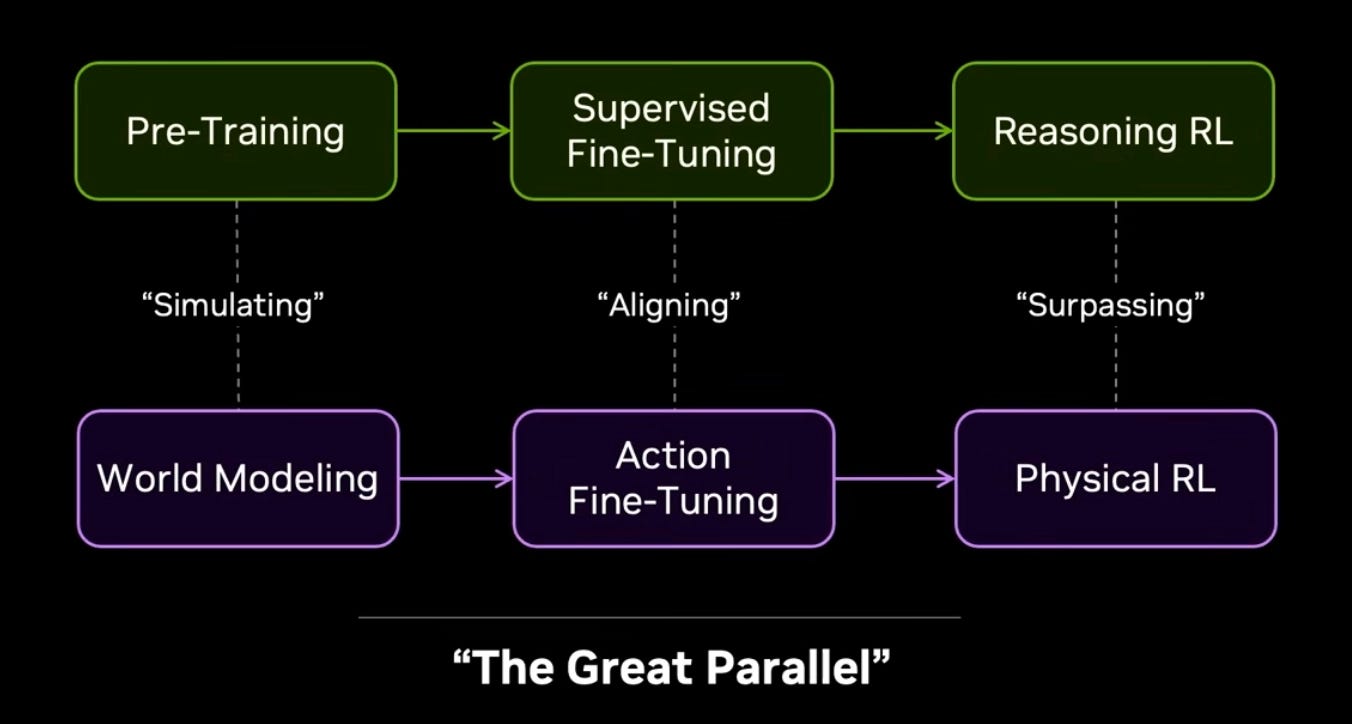
We believe that two structural bottlenecks are preventing similar convergence of pre-training in embodied AI.
The field lacks a shared, mature evaluation system for robot control policies: LLMs converged in part because benchmarks platforms like Arena AI gave the community a common yardstick. However, Embodied AI has no equivalent yet due to structural challenges. First, the field lacks clear ground truth. Robot embodiments and tasks are far more diverse than in language, and success is often ambiguous: if two robots pick and place an object in different ways, neither is obviously better, and no single metric captures generalization**.** Secondly, real world testing remains the gold standard for evaluation, but is very costly and unscalable. Third, most benchmarks evaluate robots on atomic operations: pick and place with specific objects, navigation in a known floor plan etc. There is a benchmark overfitting dynamic where the community iterates models specifically against known evals, which inflates the performance without improving the underlying generalization capability.
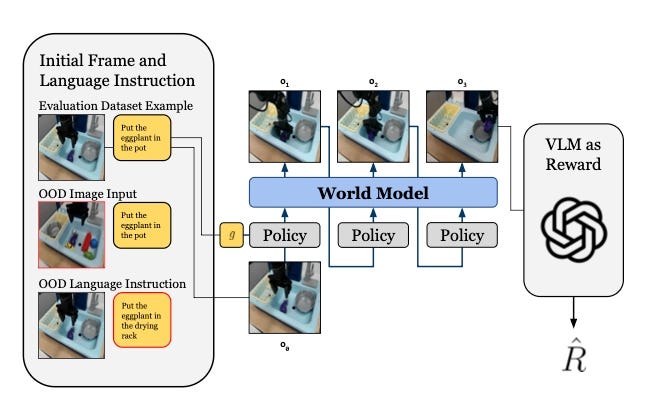
There is increasing demand to develop more scalable simulation benchmarks, but the sim-to-real gap is still significant, and requires manual effort to improve in generalization. One exciting research direction is represented by WorldGym from Sherry Yang Lab, a world-model-based policy evaluation environment that replaces costly real-world robot testing for evaluating existing robot policies. RoboArena is another promising approach for the field published in 2025. The core insight is borrowed from LLM evaluation (Chatbot Arena)—instead of fixed benchmarks, use crowd-sourced, double-blind pairwise comparisons. However, it’s restricted to DROID platform hardware, which restricts who can participate, and the coverage for tasks is still very limited compared to mature ML benchmarks. We believe that until evaluation matures and the benchmark-to-deployment performance gap gets closer, model divergence is the rational equilibrium.
The capital structure of the field actively sustains divergence: AMI Labs raised $1.03B on a JEPA/latent-space thesis. World Labs raised $1.0B on explicit 3D representations. Rhoda raised $450M on their Direct Video-Action model. Physical Intelligence raised $600M on VLAs. Each company has the runway to let its thesis play out for years before market pressure forces a decision, and there is little incentive to open source any research advancement.
Despite the structural argument for long-lasting divergence, there are early signs of convergence.
On the video generation based world model front, diffusion + autoregressive hybrid model is a common approach: Architecturally, the field historically pursued both diffusion and autoregressive generative backbones. Diffusion models are the primary backbone for modern video generation because their iterative denoising naturally models continuous, temporally coherent outputs. On the other hand, autoregressive approaches benefit from strong causal uncertainty, the ability to do efficient tree search for reasoning, and flexible horizon training [ref]. However, it suffers from error propagation as it must condition on its own imperfect predictions. To reconcile this difference, we are increasingly seeing hybrids between the two. At a NeurIPS 2025 world model workshop, Yilun Du noted that methods like Diffusion Forcing assign an independent noise level to each token, allowing the near future to be denoised more fully while the far future is kept relatively noisy. The result is a probabilistic sequence model with the flexibility of next-token prediction yet capable of the long-horizon guidance of full-sequence diffusion
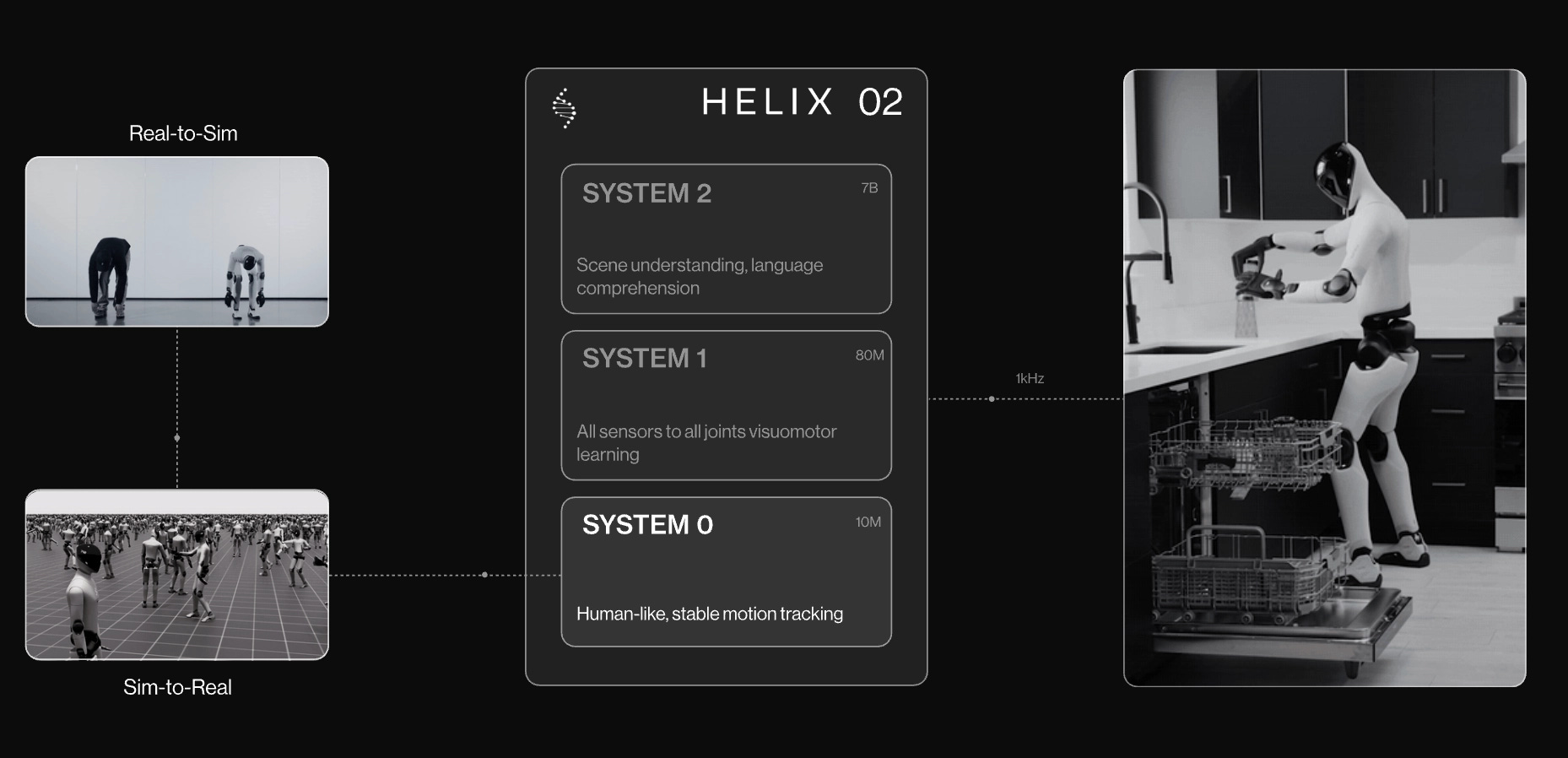
When we speak real-time control, hierarchical systems remain the practical solution towards that so far: The framing parallels Kahneman’s dual-process theory of human cognition: a fast System 1 producing reactive action, and a slower System 2 handling semantics, long-horizon reasoning, and planning. Two forces explain this convergence. First, there is a fundamental frequency gap between semantic planning and raw motor execution. Given the current compute limitations, it is impractical for a monolithic model to simultaneously encode internet-scale priors and close a 200 Hz control loop on commodity hardware. Second, hierarchical systems enable modular generalization across embodiments. Reasoning and general locomotion are largely shared across robot bodies, so the abstract upper tiers can be reused while embodiment-specific fine-tuning is concentrated in the lower tiers handling manipulation and joint control. However, the counterargument for end-to-end models, defined as training the whole network in a single gradient pass, is that they avoid the information loss introduced at the interfaces between separately trained tiers and let the system optimize jointly rather than worrying about how gradients propagate across module boundaries.
While many companies are betting on pre-training to solve generalization, in the near term, before full convergence on the pre-training paradigm arrives, the durable position belongs to full-stack players who own model development and forward deployment together. Companies can design bespoke data collection pipelines and leverage post-training on top of different model architectures to optimize for not only performance metrics, but concrete ROI that are tied to business outcomes. We believe in the short term, the moat is the data flywheel itself through deployment, not the architecture sitting on top.
In the longer term, if convergence follows, we would likely see a lot more activity on open-source models to close the gap with proprietary ones, potentially replaying the LLaMA-to-DeepSeek arc. This dynamic will be shaped in no small part by the strategic priorities of leading AI nations, several of which have made open-source release a core focus, accelerating the pace of capability diffusion globally. China’s deeply integrated hardware supply chain gives its ecosystem a structural cost advantage in commoditized robotics hardware that Western competitors will struggle to match on price. Together, open-source models and cheap, accessible hardware create a new deployment surface: the real opportunity then lies in solving the last-mile problem of getting capable models and hardware reliably into specific verticals, for example, healthcare, manufacturing, logistics, where data is messy, latency and ROI matters. This would catalyze a new wave of entrants who can arbitrage open weights and commoditized hardware to build defensible, vertically integrated deployment.
Opportunities for Startups
Our areas of interest map onto the two time horizons that frame this article: pre-convergence on the pre-training paradigm, the fragmented landscape we see today, and post-convergence if it ever happens, the consolidated paradigm that may follow. In the near term, before a dominant pre-training approach emerges, we see the most compelling opportunities in evaluation, targeted data curation, and full-stack, vertical-specific integrators who own model development and forward deployment together. Post-convergence, once a physical-interaction standard takes hold and value migrates down the stack, we may see new opportunities for startups driving deployment-focused optimization, whether it is about inference on edge/cloud, the memory layer, or others. However, the nuance is that funding has been highly concentrated in foundation model companies so far and many of them own the forward deployment layer already. Therefore the speed of convergence is competing with the speed of deployment, and startups may need to position early, before foundation model companies extend their deployment reach far enough to make the infrastructure layer a captured market rather than a contested one.
Pre-Convergence Era
Full-stack, vertical-specific integrators who own model development and forward deployment together
In the near term, we believe the most durable value creation in robotics will accrue to full-stack, vertical-specific integrators—companies that own model development, integrate hardware, and conduct forward deployment as a single closed loop. This conviction comes directly from what deployment reality has taught the field: the gap between a model that performs on a benchmark and one that ships value on a customer’s floor can only be closed by teams with a real production loop, and that loop cannot be constructed by any single layer of the stack acting in isolation. A model team without deployment has no access to the post-training signal that actually matures capability. A hardware team without a model has no way to know whether its units will be in use six months after shipment. A deployment team without research control cannot fix the underlying primitives when they fail on-site.
Evaluation for robot control policies is critical, and world models can be useful here
Evaluation for robot control policies is a critical and underinvested layer of the robotics stack. As discussed above, current approaches are caught in a trilemma: real-world testing is expensive and hard to reproduce at scale, handcrafted simulators require significant manual effort to maintain and suffer from sim-to-real gaps that make benchmark scores unreliable proxies for deployment performance, and narrow task-specific benchmarks fail to capture generalization. World-Gymnast proposed using world models not just for evaluation but as an environment for reinforcement learning, substantially outperforming both supervised fine-tuning and sim-based RL on real manipulation benchmarks. These approaches point toward a new paradigm where world models could serve as scalable, reproducible evaluation and post-training infrastructure, which can be a foundational capability unlock for the broader robot learning ecosystem.
Targeted data curation platforms
Multiple researchers that we spoke to have pointed out that high-quality data curation remains a key bottleneck in training robust world models. For pre-training, most world models train on internet-scale videos and robot demonstration videos. It is important to ensure the diversity across tasks, scenes, movements, and embodiments. In post-training, the need shifts to embodiment-specific data annotated with fine-grained action labels, such as hand pose estimation, to make the model controllable on a particular robot. As tasks grow more dexterous, there is a growing appetite for the incorporation of force and tactile data, along with ultra-long videos that move beyond 5-second clips for long-horizon generation.
Even with the right data, however, current world models still fall short on real-world physics understanding and hallucinate physics glitches, and as they expand into mission-critical use cases, physics-grounded, spatiotemporally consistent rollouts become non-negotiable. Yet evaluation today relies on human scalar preferences against loosely-defined rubrics like binary pass/fail rather than precise physics rewards, which can tell us which video did better but fails to identify the time, location, and category of a failure. Building a robust world model critic, we believe, requires a more granular approach to annotation, where trained experts provide reasoning traces for the spatiotemporal state changes of objects and scenes.
Better memory representations for long horizon tasks
Developing better memory representations for long-horizon robotic tasks remains an open research problem. Progress is advancing along two fronts. At the memory layer, the core challenge is what to store and how to compress it. Some interesting research work in the space such as MEM (Torne et al.) addressing this with a dual-modality approach: dense video encoding for short-horizon recall and auto-regressively updated language summaries for long-horizon semantics, while MemER (Sridhar et al.) takes a retrieval-based approach, training a VLM to nominate and cluster task-relevant keyframes spanning the full episode.
At the model layer, researchers are embedding memory directly into representational structure: explicit geometric memory (3D point clouds, NeRFs, 4D motion dynamics) conditioning the video generation backbone; continual learning via test-time training so that the model is trained to learn how to selectively compress and carry forward task-relevant information, directly addressing the KV cache explosion problem that plagues transformer-based approaches to long-horizon tasks; and JEPA-style latent prediction maintains memory as abstract embeddings, discarding low-level detail to keep memory semantically compressed and bounded.
Post-Convergence Era
Inference optimization, with edge computing to accelerate real-time control
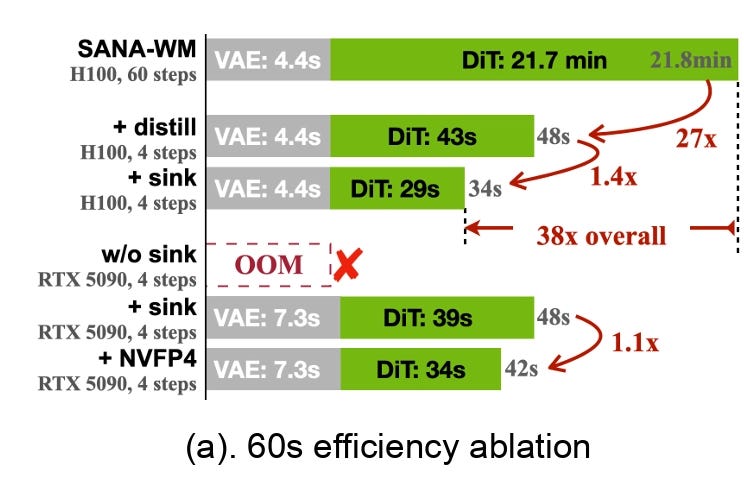
Current world models have a large inference overhead, both in terms of decode speed and compute resources required, which prevents real-time closed loop generation. For embodied AI particularly, models are largely hosted onboard to ensure latency for critical decision making. To address this, inference optimizations can happen across the stack on hardware, software and model level. On the hardware layer, Nvidia’s primary chips for robotics are the Jetson Thor (for advanced humanoid robots) and the Jetson Orin (the widely used standard for industrial and edge robotics) and we expect them to continue pushing the boundaries. Full-stack integrators who own model development may eventually purpose build their proprietary silicon to maximize model efficiency. On the software level, companies like Decart are pushing the boundaries of latency through kernel optimizations on the CUDA level, with the main applications in video generation and gaming, where real-time generation is critical. Besides that, many other techniques are being explored, such as model distillation, drifting models, and post-training quantization to improve efficiency. Nvidia’s DreamZero currently run at 7Hz using 2 GB200s, which is not practical for real-world deployment, but we expect that this can be further sped up and optimized. Nvidia’s new open-source 2.6B world model, SANA-WM, is able to generate a 60-second clip on a singular H100, achieving comparable visual quality with prior open-source baselines at 36x higher throughput. However, a caveat is that cloud speedups may not transfer to the heterogeneous compute onboard for each embodiment. And raw throughput is only a proxy: the ROI that ultimately matters is task completion rate. On the model layer, there are techniques being explored such as latent-space decoding.
If you are interested in viewing the full report on World Models for Embodied AI, find it here.
If you’re working on novel approaches to this space, we’d love to hear from you! Feel free to drop us a line at charlotte@fusionfund.com and matthew@fusionfund.com.
Subscribe for free to receive new posts and share to support our work, if you find it valuable.
Disclaimer: This post only represents personal opinion. Nothing presented within this post is intended to constitute investment advice.
 | A guest post by
|